Towards Adversarial Robustness via Debiased High-Confidence Logit Alignment
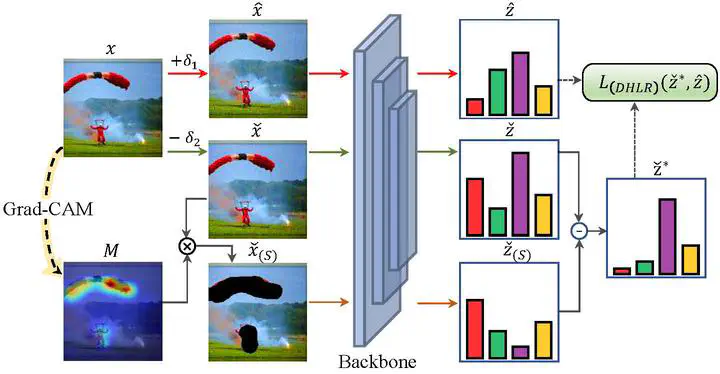 High-confidence logits alignment
High-confidence logits alignmentAbstract
Despite the remarkable progress of deep neural networks (DNNs) in various visual tasks, their vulnerability to adversarial examples raises significant security concerns. Recent adversarial training methods leverage inverse adversarial attacks to generate high-confidence examples, aiming to align adversarial distributions with high-confidence class regions. However, our investigation reveals that under inverse adversarial attacks, high-confidence outputs are influenced by biased feature activations, causing models to rely on background features that lack a causal relationship with the labels. This spurious correlation bias leads to overfitting irrelevant background features during adversarial training, thereby degrading the model’s robust performance and generalization capabilities. To address this issue, we propose Debiased High-Confidence Adversarial Training (DHAT), a novel approach that aligns adversarial logits with debiased high-confidence logits and restores proper attention by enhancing foreground logit orthogonality. Extensive experiments demonstrate that DHAT achieves state-of-the-art robustness on both CIFAR and ImageNet-1K benchmarks, while significantly improving generalization by mitigating the feature bias inherent in inverse adversarial training approaches.