Towards Adversarial Robustness via Debiased High-Confidence Logit Alignment
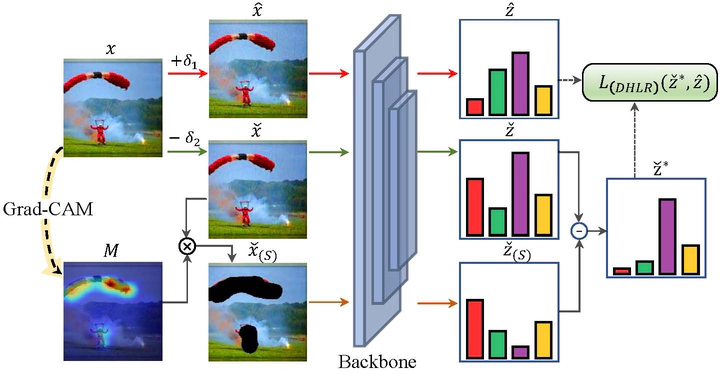 High-confidence logits alignment
High-confidence logits alignmentAbstract
Despite deep neural networks (DNNs) have achieved significant advances in various visual tasks, they remain susceptible to adversarial examples, raising serious security concerns. Recent adversarial training techniques have employed inverse adversarial attacks to generate high-confidence examples, aiming to align the distributions of adversarial examples with the high-confidence regions corresponding to their classes. However, our investigation reveals that high-confidence outputs under inverse adversarial attacks are correlated with biased feature activation, training with inverse adversarial examples causes the model to prioritize background features over foreground features. To mitigate this spurious correlation bias, we introduce Debiased High-Confidence Adversarial Training (DHAT), a novel approach that aligns the logits of adversarial examples with debiased high-confidence logits derived from inverse adversarial examples, while simultaneously restoring model attention to its normal state by foreground logit orthogonal enhancement. Extensive experiments demonstrate that DHAT achieves state-of-the-art performance and robust generalization across various vision datasets. Additionally, DHAT integrates seamlessly with existing advanced adversarial training techniques.
Type
Publication
arxiv